
Context
Convolutional neural networks (CNN) have revolutionized the field of machine learning in recent years, particularly in the area of image classification. The different applications and advances in the understanding and explainability of these models also allow us to understand their flaws: spatial problems or so-called “adversarial” (contradictory) attacks.
The limits of convolutional networks

Picasso – Guernica (source Wikiart)
For example, we can use the analogy of the faces of the Guernica by Picasso to illustrate the inability of CNN models to understand the spatial relationships between objects present in images.
If we were to transcribe into French what a CNN interprets when we submit an image of a face to it, it would look something like this:
“If in the image we find:
– One or more eyes,
– A nose,
– A mouth,
– Eyebrows …So it's a face! »
These criteria appear at first glance sufficient to correctly detect a real human face. However, if our image contains characteristics of a face, but with a somewhat original layout (4 eyes, 2 mouths, a nose on the left, vertical eyebrows, etc.), should we really let the algorithm recognize the image as a face?

We could also discuss the “adversarial” attacks » which are the fear of these models. These are disturbances that are almost invisible to the naked eye, but can radically deceive the network.
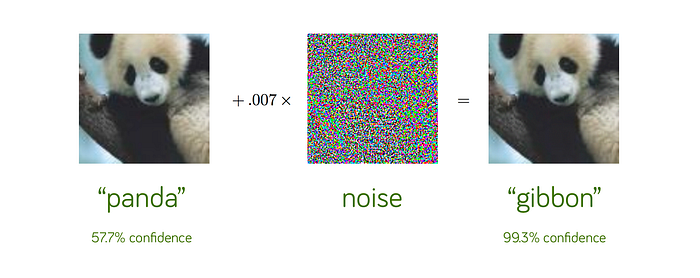
Source : https://towardsdatascience.com/breaking-neural-networks-with-adversarial-attacks-f4290a9a45aa
Innovation: the “Capsule” neuron
To overcome these problems, Geoffrey Hinton and his team proposed in 2017 an improvement to this type of model by introducing capsules to replace neurons in a standard neural network.
The capsules increase neurons by retaining a information vector rather than a simple (scalar) quantity. This vector retains much more detail: the pose, the texture, the locality…
By using a process similar to the classic CNN, the capsule network can learn more complex patterns.
Returning to our example of face detection, such a network can learn the spatial relationship between eyes, nose, and mouth, and could theoretically even understand pose (face orientation). So, the transcription in French could give this:
“If in the image we find:
– Two eyes, left or right of another eye, above the nose
– A nose, oriented vertically, in the center, under the eyes
- A mouth, oriented horizontally, under the nose and eyes
- A pair eyebrows oriented horizontally, above the eyes …So it's a face! »
Depending on the information retained in the capsule vector, the network can in theory be sensitive or not to the characteristics that can be interpreted from this information.
Since then, numerous papers have been published on the subject to propose improvements, adaptations to various use cases (other than 2D), as well as the sensitivity of capsules to “adversarial” attacks.
We recommend that you read this article available on medium.com for more details on their history and operation: https://medium.com/ai³-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b



{kind=link}