
Aqson
Context
Definitions
First of all, before going into details, let's start by defining these terms to clearly distinguish their difference:
- Interpretability is to be able to understand how the model works by providing information about the Machine Learning model as well as the data used. Interpretability is dedicated to ML or data experts.
- Explainability consists of being able to explain why the model gave a particular prediction by providing information in a complete semantic format accessible to a neophyte or technophile user
Interpretability with SHAP
We will now focus more precisely on an interpretability method whose functioning we will explain as well as its positive and negative points: SHAP.
The SHAP method is based on game theory. To put it simply, it makes it possible to measure the impact on the prediction of adding a variable (all things being equal) thanks to permutations of all possible options.
For example, if we want to estimate the effect of a person's gender on a prediction, we will test the difference in predictions between gender = Man and gender = Woman on each possible combination of other variables. Visually, we can see below the impact of the “cat ban” on the price of an apartment.

As output, we obtain a SHAPley value which represents the impact of a variable on the prediction. In the example above, a high SHAPley value will indicate that the value of the variable tends to increase the price of the apartment.
Applying SHAP to Titanic data
We will now show you how SHAP concretely allows us to interpret the results of an XGBoost algorithm.
This example will focus on Titanic data (https://www.kaggle.com/c/titanic/data), for which the goal is to predict the surviving passengers using data concerning them with for example: Sex_female=gender, Pclass=class on the boat, Fare=ticket price, Age=age… The value to be predicted corresponds to the Survived variable which takes the value 1 for the passenger's survival.
The graph below shows all SHAPley values per observation and per observation. The color of the points corresponds to the value of the variable and the horizontal positioning of the points corresponds to the SHAPley value.
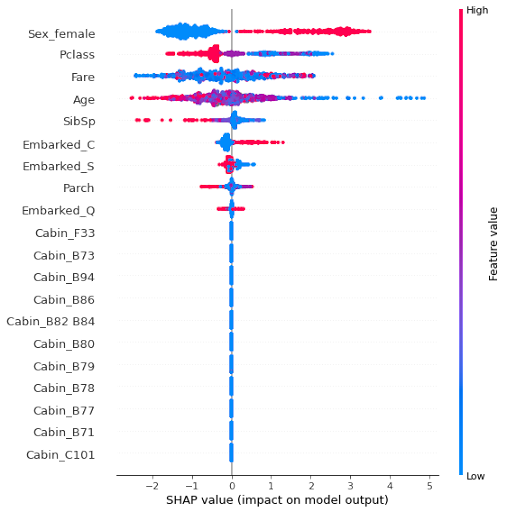
Analysis according to Sex
We can see for example, that for the variable Sex_female, if the value is 0 (blue point, the passenger is a man), then the SHAPley values are negative (located on the left) therefore to the disadvantage of the Survived prediction (1) .
On the contrary, if the value is 1 (red dot, the passenger is a woman), the SHAPley values are positive (located on the right) therefore in favor of the Survived prediction (1).
Conclusion : you have a better chance of surviving the sinking of the Titanic if you are a woman!
We find these results in the graph below where we clearly see the two modalities and their significant impact in the prediction.

Analysis by age
On the following graph, we clearly see that passengers aged less than 10 years had the greatest chance of surviving since it is when the x axis is less than 10 that the SHAPley values are the highest and therefore the most in favor of survival (since they increase the value of the prediction)

Crossing of variables
It is also possible to cross variables. For example here, we want to see the impact on the prediction of the variable PClass and Sex_female. On the ordinate we have the SHAPley values, on the abscissa the variable PClass and in color the variable Sex_female. What we see is that class 1 has the greatest chance of survival, then comes the 2nd and finally the 3rd class. In addition to this, in the first and second classes, we see that women have the greatest chance of survival (in red) because their SHAPley values are above those of men. Which is reversed in 3rd class (!)

Explainability with SHAP
It is also possible to explain what the drivers were to lead to the final prediction for a particular individual. It is therefore a local explanation and not a global one.
In the graph below, we can see the impact of each of the characteristics of the chosen individual and how these characteristics impact the prediction. In blue the characteristics having a negative SHAPley value therefore in favor of survival and in red the characteristics having a positive SHAPley value therefore in favor of survival. These SHAPley values are additive. For the individual below, we see that the fact that she was a woman increased her prediction of survival, which was also supported by the fact that she was in first class.

Conclusion
To conclude on the SHAP method, we will take stock of the positive and negative points of this method:
SHAP Benefits : The major advantage of the SHAP method is that it guarantees that the prediction is fairly distributed among the variables, it is therefore a robust method (based on solid theory) and reliable if one wishes to carry out an audit of model for example. In addition, the graphics are clean and readable, making them perfect for use with a non-expert client.
SHAP Disadvantages : On the other hand, its main disadvantage is the calculation time which increases exponentially with the number of variables available (2^k possible coalitions). This can be compensated for by sampling but this then increases the variance. The explanations deduced from SHAP are always conditional on “knowing the remaining set of variables”, that is to say that the method systematically uses all the variables. The fact of not having an output model, unlike LIME for example, means that for a new observation, the explanation must be restarted. And finally the fact that certain values are simulated randomly can generate unrealistic points: for example age = 15 and major = Yes, because the simulations are random and do not take into account the correlations between the variables.
Before leaving us...
SHAP is not the only method that exists in this area. As mentioned previously LIME is also a method that uses features to explain the results of the model. On the other hand, unlike the SHAP method, it consists of re-creating a linear model using simulated observations around the point of interest. As you can see in the graph below other methods can be used depending on the structure of your project.



