
Les réseaux de neurones convolutifs (CNN) ont ces dernières années révolutionné le domaine de l’apprentissage automatique, notamment dans le domaine de la classification d’images. Les différentes applications et avancées dans la compréhension et l’explicabilité de ces modèles nous permettent aussi d’en comprendre ses défauts : problèmes de spatialité ou attaques dites « adversariales » (contradictoires).

Picasso – Guernica (source Wikiart)
On peut par exemple utiliser l’analogie des visages du Guernica de Picasso pour illustrer l’incapacité des modèles CNN à comprendre les relations spatiales entre les objets présents dans les images.
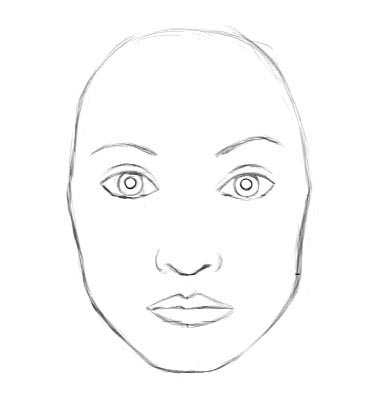
Si l’on devait retranscrire en français ce qu’interprète un CNN quand on lui soumet une image de visage, cela donnerait quelque chose de la sorte :
« Si dans l’image on trouve :
– Un ou plusieurs yeux,
– Un nez,
– Une bouche,
– Des sourcils …
Alors c’est un visage ! »
Ces critères paraissent à première vue suffisants pour détecter correctement un vrai visage humain. Pourtant, si notre image contient les caractéristiques d’un visage, mais avec une disposition un peu originale (4 yeux, 2 bouches, un nez sur la gauche, des sourcils verticaux…), doit-on vraiment laisser l’algorithme reconnaître l’image comme un visage ?

On pourrait aussi discuter des attaques « adversariales » qui sont la hantise de ces modèles. Ce sont des perturbations quasi invisible à l’œil nu, mais qui peuvent radicalement tromper le réseau.

Pour pallier ces problèmes, Geoffrey Hinton et son équipe proposent en 2017 une amélioration à ce type de modèle en introduisant les capsules en remplacement de neurones dans un réseau de neurones standard.
Les capsules augmentent les neurones en retenant un vecteur d’informations plutôt qu’une simple quantité (scalaire). Ce vecteur retient beaucoup plus de détails : la pose, la texture, la localité…
En utilisant un procédé similaire au CNN classique, le réseau à capsules peut ainsi apprendre des schémas plus complexes.
Pour revenir à notre exemple de la détection de visage, un tel réseau peut apprendre la relation spatiale entre les yeux, le nez et la bouche, et pourrait même en théorie comprendre la pose (l’orientation du visage). Ainsi, la retranscription en français pourrait donner cela :
« Si dans l’image on trouve :
– Deux yeux, à gauche ou à droite d’un autre œil, au-dessus du nez
– Un nez, orienté verticalement, au centre, sous les yeux
– Une bouche, orientée horizontalement, sous le nez et les yeux
– Une paire de sourcils orientés horizontalement, au-dessus des yeux …
Alors c’est un visage ! »
En fonction des informations retenues dans le vecteur de la capsule, le réseau peut en théorie être sensible ou non aux caractéristiques qui sont interprétables depuis ces informations.
Depuis de nombreux papiers ont été publiés sur le sujet pour proposer des améliorations, des adaptations à des use case divers (autre que la 2D), ainsi que la sensibilité des capsules aux attaques « adversariales ».
Nous vous recommandons de lire cet article disponible sur medium.com pour plus de détails sur leur histoire et fonctionnement: https://medium.com/ai³-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
Découvrez nos articles sur les dernières tendances, avancées ou applications de l’IA aujourd’hui.













{kind=link}